
Problem
Web agents have quickly become a popular way to automate tedious online workflows. Model labs (OpenAI, Anthropic, Google, Yutori) are all racing to build full-stack agents powered by computer use models (CUA) that can book flights, purchase items, or execute complex enterprise tasks.
However, evaluating these models has remained a persistent bottleneck. At Halluminate, we built WebBench, a real-world benchmark that tests agents directly on live websites. It gave us a valuable snapshot of current capabilities, but it also exposed how fragile real-site evaluation is. The benchmark was hard to reproduce for a variety of reasons including:
- CAPTCHAs and bot checks firing unpredictably
- Login, authentication, and payment flows that block workflows
- Constantly changing data (ex. prices, inventory, timestamps, search results)
- UI changes
All of this creates a tremendous amount of noise. It becomes difficult to benchmark CUA models on real world web tasks, perform clean error analysis, or use these environments for RL.
Solution
To solve this problem, we partnered with Yutori to build Westworld: a suite of realistic web app simulators used to evaluate web agents.
Simulators have three structural advantages over real website evaluation:
- Reproducibility: every agent sees the exact same state
- Determinism: no CAPTCHAs, DOM drift, randomized search results, or data decay
- Control: ability to scale difficulty, inject edge cases, log every step, and run RL with hosted sims without noisy/breaking site changes
Westworld consists of 100 tasks across five simulated environments. Each environment is modeled after a common workflow on popular real-world sites such as:
- Noodle Flights and Travelpedia: full end-to-end simulations of flight-search and booking flows, including multi-leg routes, connecting flights, fare classes, constraints, and edge cases.
- GoodBuy, Azora, and Megamart: purchasing simulators that capture the structure of modern ecommerce checkout flows
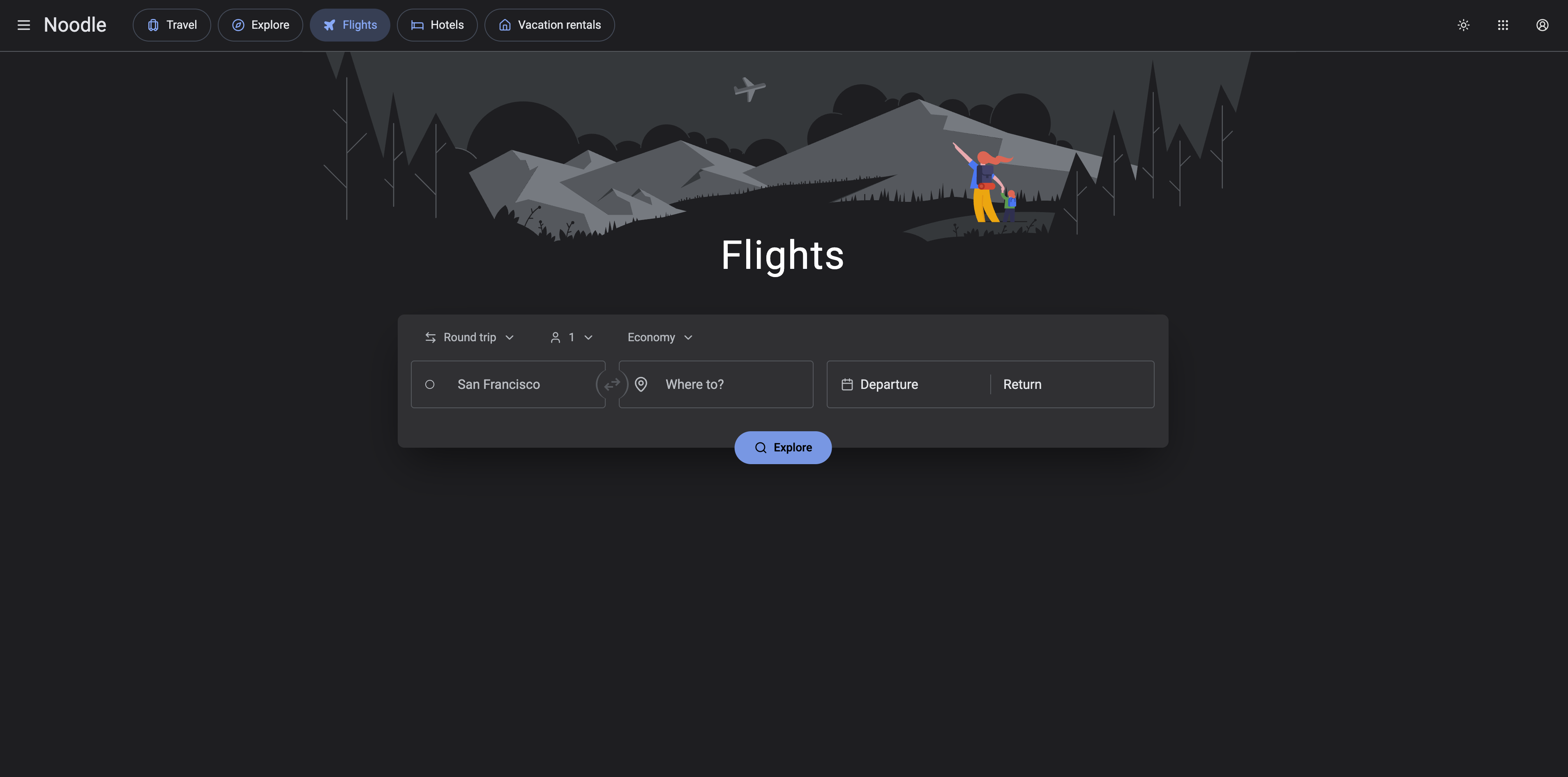
Noodle Flights
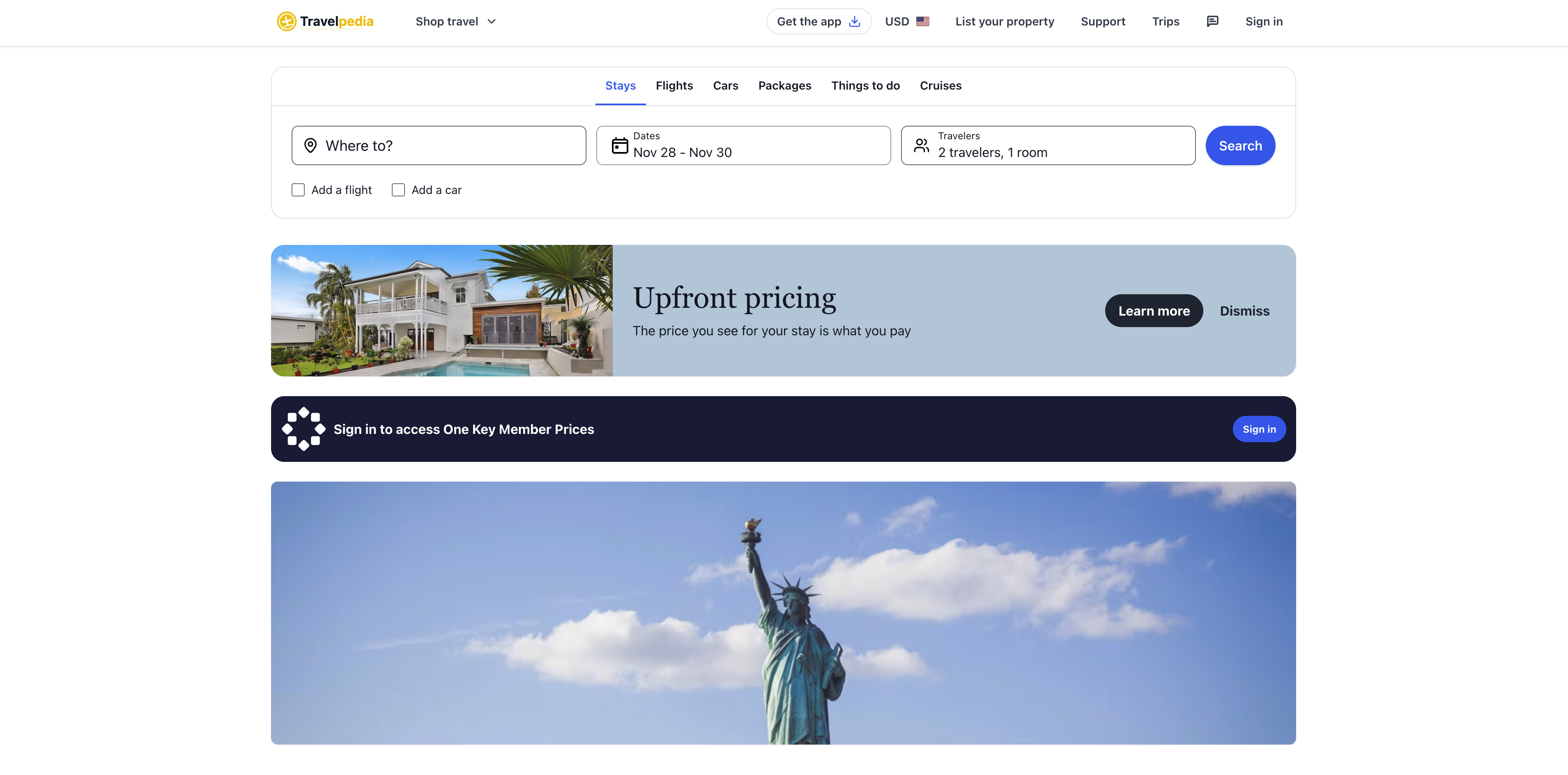 Travelpedia
Travelpedia
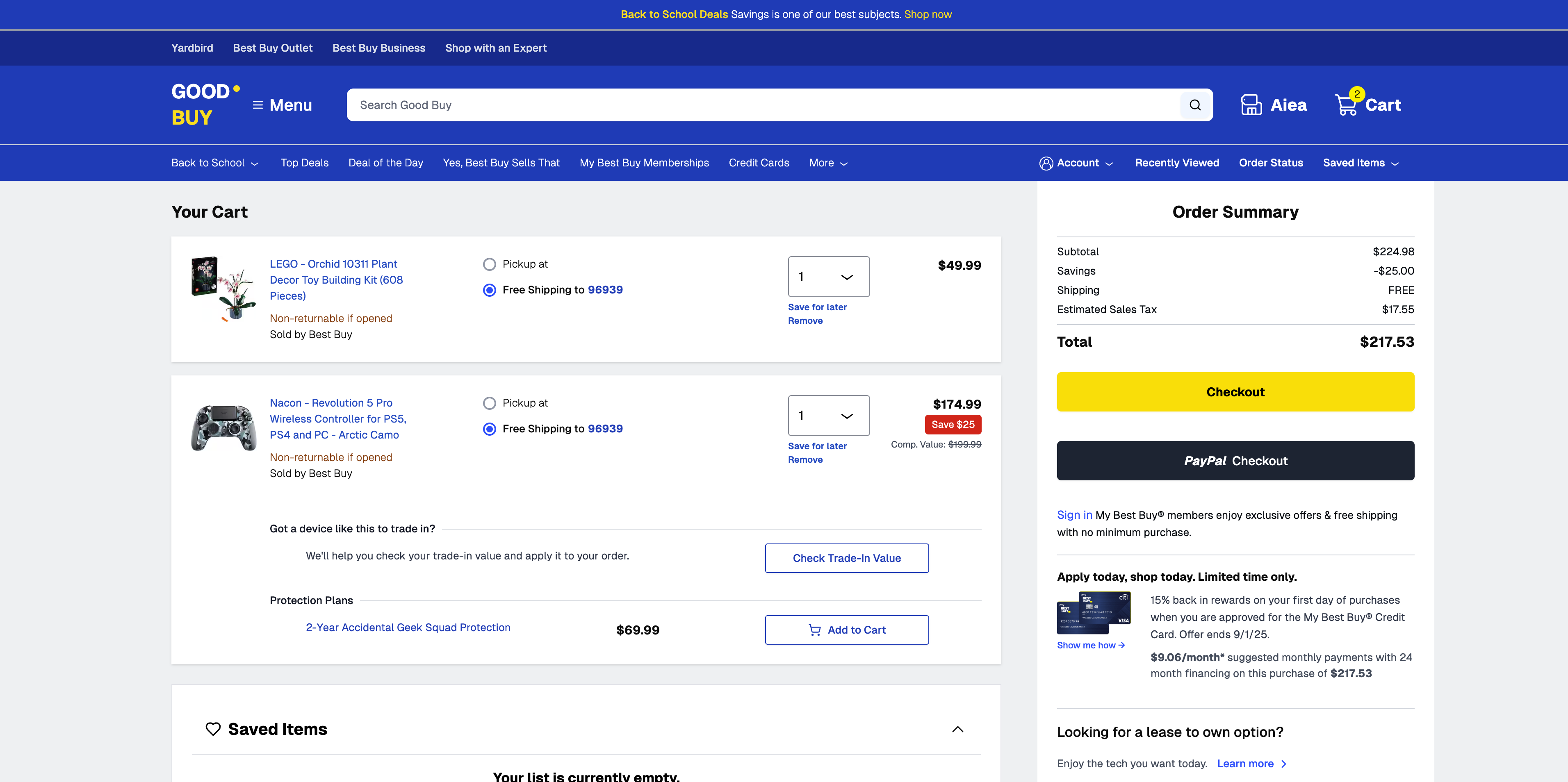 GoodBuy
GoodBuy
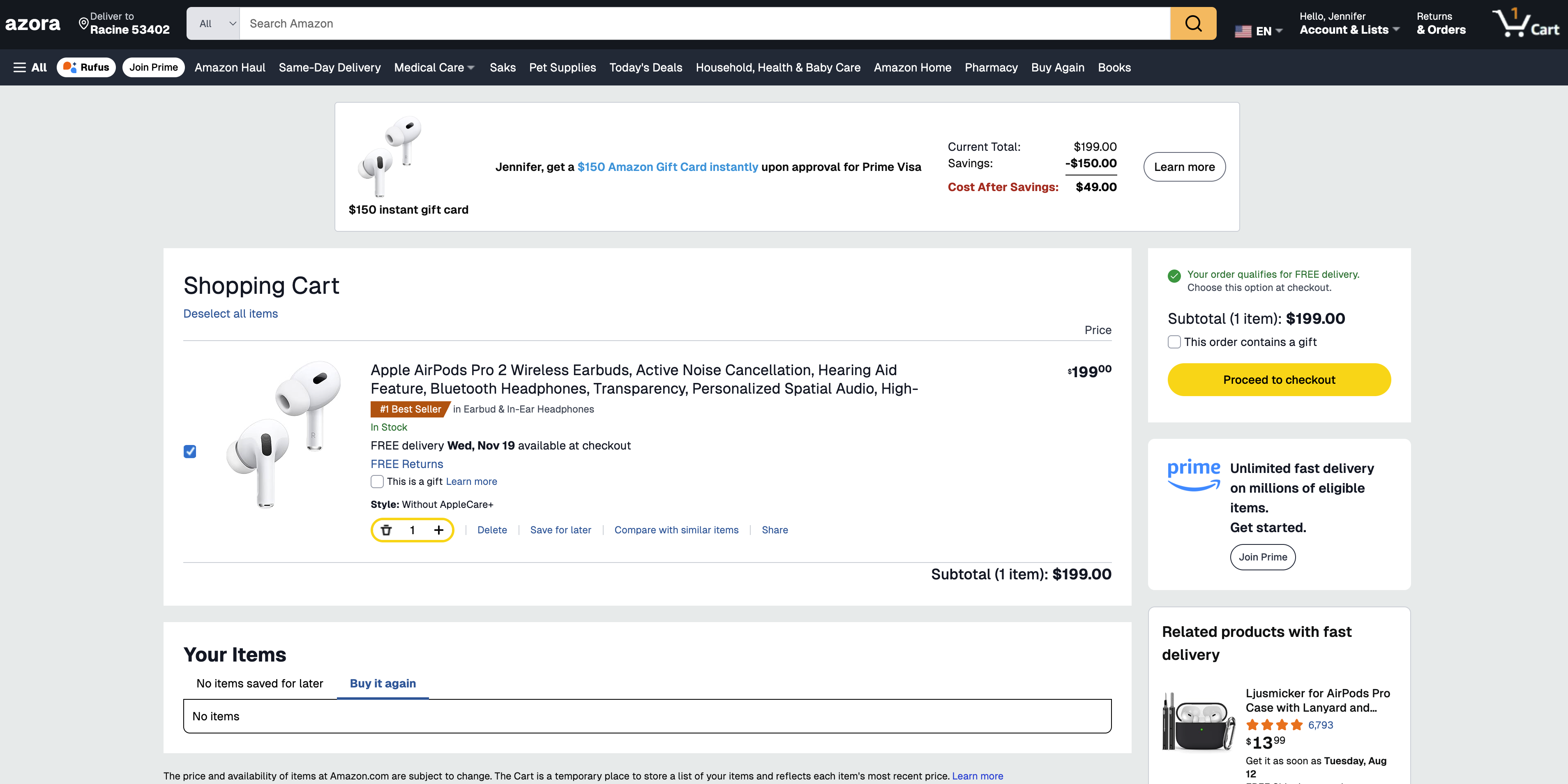 Azora
Azora
 Megamart
Megamart
Simulator & Task Design
Most simulation efforts take an app-centric approach: rebuild a whole site feature-for-feature, then create tasks on top. This approach gives broad coverage, but also explodes complexity. The result may end up simulating large parts of the UI that have no relevancy for real agent queries.
We take the opposite approach: task-centric simulation. Broadly this entails:
- Identifying the set of high-value user workflows (flight search, item comparison, checkout, etc.).
- Simulating the interaction patterns that matter for those workflows
- Ignore the parts of the app that don't contribute to learning or evaluation.
For example in flight booking, real airline sites contain countless surfaces (ex. loyalty pages, ads, seat maps, upsells) but the core workflow is small: pick origin/destination, choose dates, run a search, filter options, select an itinerary, and confirm. Our simulators model only these essential steps with structured selectors and deterministic search results. This keeps the environment focused on the actual skills we want to measure: search, filtering, reasoning, and multi-step execution.
On task design, each simulator is built around a structured task generation pipeline which includes:
- Task Template: We start from real-world production queries like "find the cheapest nonstop flight," "compare two products," "purchase item X before date Y." These become reusable templates.
- Synthetic Generation: Templates are filled using synthetic but realistic data: routes, prices, product attributes, availability windows, etc. The generator varies in difficulty, ambiguity, and distractors.
- Date & Time Realism: Simulators compute dates relative to the actual runtime date (e.g., allowable shipping windows, valid departure dates). This keeps tasks dynamic while still fully deterministic.
The result is a large, controlled distribution of tasks that reflect the kinds of problems real web agents must solve.
| Simulator | Template | Task |
|---|---|---|
| Noodle Flights | Find the cheapest one-way direct flight from TSE to YYZ on {date} and return its flight number and price. | Find the cheapest one-way direct flight from TSE to YYZ on September 08, 2026 and return its flight number and price. |
| Travelpedia | Search for a hotel in Rio de Janeiro. Set check-in date to {checkin} and check-out to {checkout}. Set 3 adults as travelers. | Search for a hotel in Rio de Janeiro. Set check-in date to June 21, 2026 and check-out to July 01, 2026. Set 3 adults as travelers. |
| Good Buy | Purchase the items in the cart and deliver them to {name}. Use {name}'s payment info. Set the delivery instruction dropoff location to {drop_off_type} and property type to {property_type}. Your job is done when the order is successfully placed. Use guest checkout. User info: {user_info}. | Purchase the items in the cart and deliver them to Violet Ritchie. Use Violet Ritchie's payment info. Set the delivery instruction dropoff location to front door and property type to apartment. Your job is done when the order is successfully placed. Use guest checkout. |
| Azora | Hey, can you order these AirPods for me? Ship them to {delivery_recipient}. Use the card ending in {card_ending}. If you need to add a new card, make sure the billing address matches the card owners address. Also, set the delivery date to {delivery_date}. Let me know once the order is placed. User info: {user_info} | Hey, can you order these AirPods for me? Ship them to Jennifer Morrison. Use the card ending in 6685. If you need to add a new card, make sure the billing address matches the card owners address. Also, set the delivery date to Tuesday, Nov 18. Let me know once the order is placed. |
| Megamart | Purchase this vase and deliver it to {delivery_address}. Use {payment_method}. I want it delivered {delivery_date}. Your job is done when the order is successfully placed. You may need to reference the following user info: {user_info} | Purchase this vase and deliver it to the default delivery address. Use the default payment method. I want it delivered Saturday, Nov 15. Your job is done when the order is successfully placed. |
Verifiable Rewards
We employ RLVR-style unit tests that deterministically evaluate the agent's final state. Complete access to the simulator's underlying data allow us to compute and check ground truth programmatically, eliminating dependence on live-site scraping and preventing label drift as real websites evolve.
Broadly our verifiers fall into three buckets:
- State-Based Unit Test: We record actions taken on the simulator that change a backend database. The verifier then compares these to expected ground truth states given the task requirements.
- Component-Level Verification: For structured selectors (i.e. dates, airports, product attributes) we verify correctness by pulling the state at the component. For example: given a flight search task, we can verify that the agent completed the task correctly by pulling the state of the search component and comparing the actual values with expected values.
- Real-Time Calculated Ground Truth: For tasks that require comparison and/or verifying against the agent's response (ex. Find the cheapest flight from A to B on the following weekend), the agent attempts to solve the problem, we query the simulator to find the ground truth, then compare this to the agent's answer.
Different verifier approaches work best for different tasks. Workflows that require WRITE actions are best verified with State-Based and Component-Level verifications (ex. Submitting purchase order, flight booking, etc). On the other hand, tasks that require finding some ideal answer and returning a recommendation are best verified with ground truth matching.
State-Based Verifier
async def compute(self) -> FinalResult:
"""Compute verification score by comparing simulator state to task requirements."""
# 1. Retrieve current state from simulator (updated by agent actions)
current_state = await self._get_current_state()
# 2. Parse raw state into structured objects
state_obj = create_application_state_from_dict(current_state)
# 3. Verify state matches task requirements
result = verify_basic_checkout_complete(self._ground_truth, state_obj)
# 4. Return deterministic score based on verification
if result.passed:
return FinalResult(
score=1.0,
reasoning="Passed all checks",
current_state=current_state,
ground_truth=self._ground_truth,
)
else:
return FinalResult(
score=0.0,
reasoning="Failed (verification): " + "; ".join(result.failures),
current_state=current_state,
ground_truth=self._ground_truth,
)
Component-Level Verifier
def verify_flight_search_complete(state: ApplicationState, params: FlightSearchParams) -> VerificationResult:
"""
Component-level verification: check each structured selector individually.
Each component (origin, destination, dates, cabin class, passengers)
is verified separately for granular error reporting.
"""
errors: List[str] = []
# Component 1: Verify trip type
if is_specified(params.trip_type):
if state.trip_type != params.trip_type:
errors.append(f'Trip type mismatch. Expected "{params.trip_type}", found "{state.trip_type}"')
# Component 2: Verify origin location (with airport/city fallback logic)
if is_specified(params.origin):
origin_matches = location_matches_with_sophisticated_fallback(
params.origin,
params.origin_airport,
params.origin_city,
params.origin_has_multiple_airports,
state.from_location,
)
if not origin_matches:
expected_display = f'"{params.origin}"'
if params.origin_airport:
expected_display += f' or "{params.origin_airport}"'
if params.origin_city and not params.origin_has_multiple_airports:
expected_display += f' or "{params.origin_city}"'
errors.append(f'Origin location mismatch. Expected {expected_display}, found "{state.from_location}"')
# Component 3: Verify destination location
if is_specified(params.destination):
destination_matches = location_matches_with_sophisticated_fallback(
params.destination,
params.destination_airport,
params.destination_city,
params.destination_has_multiple_airports,
state.to_location,
)
if not destination_matches:
expected_display = f'"{params.destination}"'
if params.destination_airport:
expected_display += f' or "{params.destination_airport}"'
if params.destination_city and not params.destination_has_multiple_airports:
expected_display += f' or "{params.destination_city}"'
errors.append(f'Destination mismatch. Expected {expected_display}, found "{state.to_location}"')
# Component 4: Verify departure date
if is_specified(params.departure_date):
if not state.departure_date:
errors.append("Departure date not set")
else:
if not dates_match(params.departure_date, state.departure_date):
errors.append(
f"Departure date mismatch. Expected {params.departure_date}, found {state.departure_date}"
)
# Component 5: Verify return date (for round-trip)
if is_specified(params.return_date):
if state.trip_type == "round-trip":
if not state.return_date:
errors.append("Return date not set for round-trip")
else:
if not dates_match(params.return_date, state.return_date):
errors.append(f"Return date mismatch. Expected {params.return_date}, found {state.return_date}")
# Component 6: Verify passenger counts (each checked individually)
if is_specified(params.adults):
if state.passengers.adults != params.adults:
errors.append(f"Adults count mismatch. Expected {params.adults}, found {state.passengers.adults}")
if is_specified(params.children):
if state.passengers.children != params.children:
errors.append(f"Children count mismatch. Expected {params.children}, found {state.passengers.children}")
if is_specified(params.infants):
if state.passengers.infants != params.infants:
errors.append(
f"Infants (in seat) count mismatch. Expected {params.infants}, found {state.passengers.infants}"
)
if is_specified(params.lap_infants):
if state.passengers.lap_infants != params.lap_infants:
errors.append(
f"Infants (on lap) count mismatch. Expected {params.lap_infants}, found {state.passengers.lap_infants}"
)
# Component 7: Verify travel class (cabin class)
if is_specified(params.travel_class):
if state.travel_class != params.travel_class:
errors.append(f'Travel class mismatch. Expected "{params.travel_class}", found "{state.travel_class}"')
# Component 8: Verify form completeness
if not state.is_search_ready:
errors.append("Search form is not complete - missing required fields")
return VerificationResult(
passed=len(errors) == 0,
details={"errors": errors, "expected": params.__dict__, "actual": actual_summary}
)
def location_matches_with_sophisticated_fallback(
expected_code: str, expected_airport: str, expected_city: str,
has_multiple_airports: bool, actual: str
) -> bool:
"""
Component-level location matching with fallback logic:
1. Try airport code match (e.g., "LAX")
2. Try airport name match (e.g., "Los Angeles International Airport")
3. For single-airport cities: also accept city name match
4. For multi-airport cities: require code/airport name (more strict)
"""
# 1. Always try to match airport code first
if bidirectional_substring_match(expected_code, actual):
return True
# 2. Always try to match airport name
if bidirectional_substring_match(expected_airport, actual):
return True
# 3. For cities with multiple airports: only accept code/airport name matches
if has_multiple_airports:
return False
# 4. For cities with single airport: also accept city name matches
if bidirectional_substring_match(expected_city, actual):
return True
return False
Ground Truth Verifier
def get_runtime_ground_truth(task_data: Dict[str, Any], api_base_url: Optional[str] = None) -> Dict[str, Any]:
values = task_data.get("values", {})
origin = values.get("origin")
destination = values.get("destination")
date = values.get("date")
task_description = task_data.get("task", "")
# Check if task requires direct flights
require_direct = "direct" in task_description.lower()
# Step 1: Query the simulator API at runtime
flight_data = query_google_flights_simulator(origin, destination, date, api_base_url, require_direct)
flights = flight_data.get("departingFlights", [])
# Step 2: Deterministically compute the cheapest flight(s)
cheapest_flights = find_cheapest_flights(flights, require_direct)
if cheapest_flights:
cheapest_price = cheapest_flights[0].get("priceUsd", 0)
flight_numbers = [f.get("flightNumber", "UNKNOWN") for f in cheapest_flights]
return {
"flightNumbers": flight_numbers, # Ground truth: computed answer
"price": cheapest_price, # Ground truth: computed answer
"totalFlights": len(flights),
"cheapestFlightsCount": len(cheapest_flights),
"requireDirect": require_direct,
}
Results
We ran Westworld in partnership with Yutori, testing their agent harness and 4 different models.
| Model | Azora | Good Buy | Megamart | Travelpedia | Noodle Flights | Average (%) |
|---|---|---|---|---|---|---|
| Gemini 2.5 pro | 52.5 | 73.8 | 23.8 | 57.5 | 66.3 | 54.8 |
| Claude Sonnet 4.0 | 38.3 | 31.7 | 28.3 | 90.0 | 73.3 | 52.3 |
| Claude Sonnet 4.5 | 63.3 | 30.0 | 71.7 | 88.3 | 85.0 | 67.7 |
| Yutori n1 | 91.7 | 73.3 | 100.0 | 83.3 | 81.7 | 86.0 |
Across the five Westworld simulators, we observe large performance differences between general-purpose foundation models and agents trained specifically for web use. Claude Sonnet 4.0 averages 52.3%, performing well on travel workflows but struggling on ecommerce environments. Gemini 2.5 pro has the opposite performance, excelling in ecommerce environments but struggling on flight booking workflows. Claude Sonnet 4.5 improves to 67.7%, with notable gains on Noodle Flights and Megamart.
The strongest results come from Yutori n1, whose agent was trained directly inside Westworld, which achieves an average of 86.0%, including 91.7% on Azora and 100% on Megamart. On top of achieving SOTA on Westworld, Yutori also saw strong sim to real transfer as their agent improved performance on real world sites in flight booking and e-commerce. Read more here.
An interesting pattern in the results is that performance across simulators is patchy; models improve in sharp spikes on certain workflows rather than gradually improving across the board. This is most evident when comparing Sonnet 4.5 to Sonnet 4.0. Most of Sonnet 4.5's gains come from large jumps on the ecommerce simulators (Megamart and Azora), while performance on GoodBuy actually regresses. And despite strong ecommerce gains, Sonnet 4.5 shows only minor improvement on Noodle Flights and a regression on Travelpedia. This uneven progress suggests the improvements are domain-specific, likely reflecting differences in the training data or RL environments that each product research team chooses to prioritize.
Error Analysis
UI Grounding
Web agents continue to struggle with small precise click motions for complex UI components. The biggest example of this behavior is calendar date picking. Even with robust post-training, there remain reliability issues with these workflows.
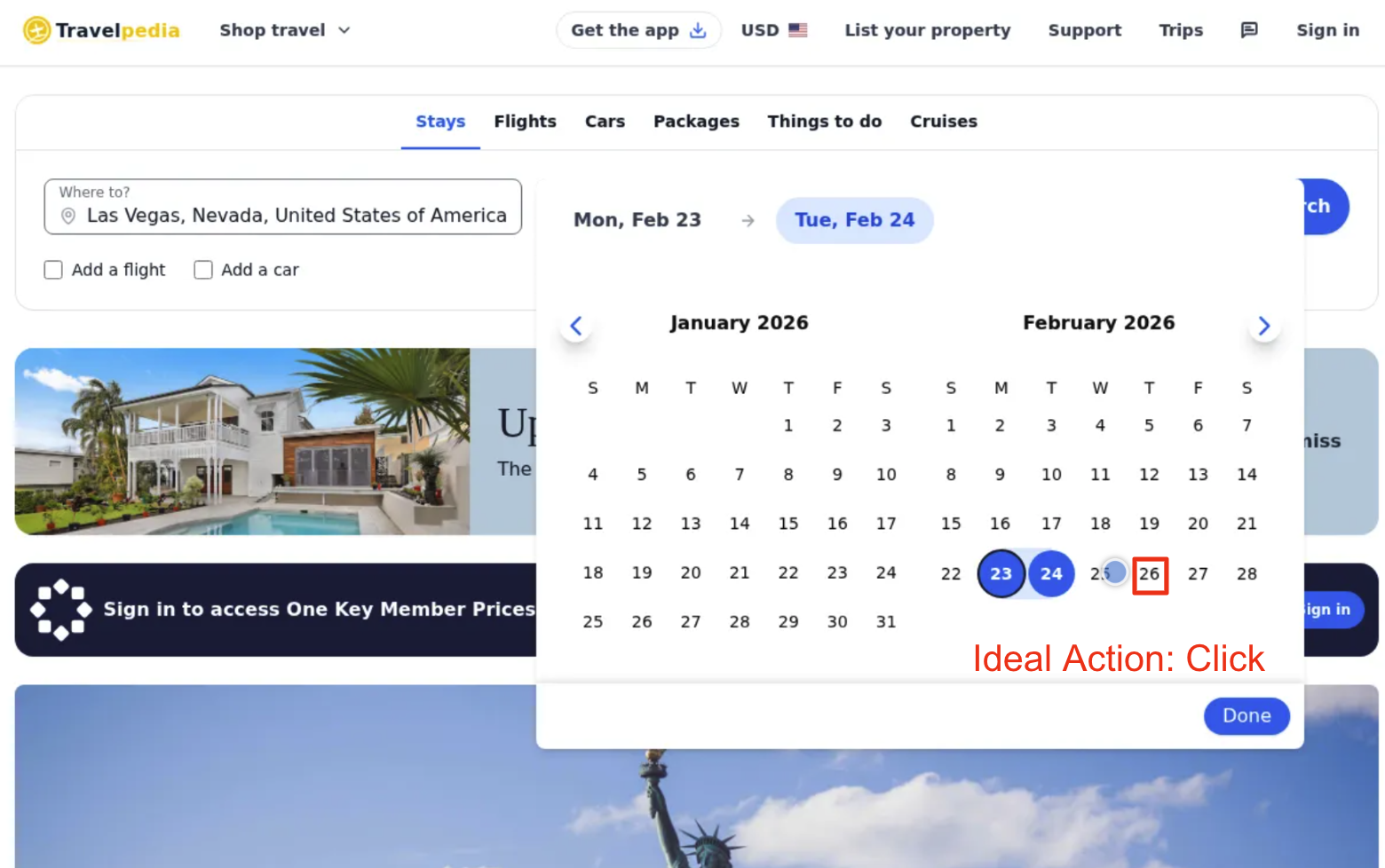
Task: Book a midweek stay from the fourth Tuesday to Thursday of February 2026 in Las Vegas. The booking is for 2 adults. Once you have successfully submitted the search, your task is complete - do not take any further actions.
Model Thoughts: Good! Now I see "Mon, Feb 23" and "Tue, Feb 24". Now I need to click on the 26th to extend the range. Let me click on the 26th.
Reasoning Errors
For longer trajectory web navigation tasks, we often saw web agents fall short on specific task-level instruction following and reasoning. For example, on Noodle Flights we ask agents to do long-horizon planning and selection by researching multiple flights. However, for the 3rd leg of search, the agent fails to choose the cheapest flight as requested.
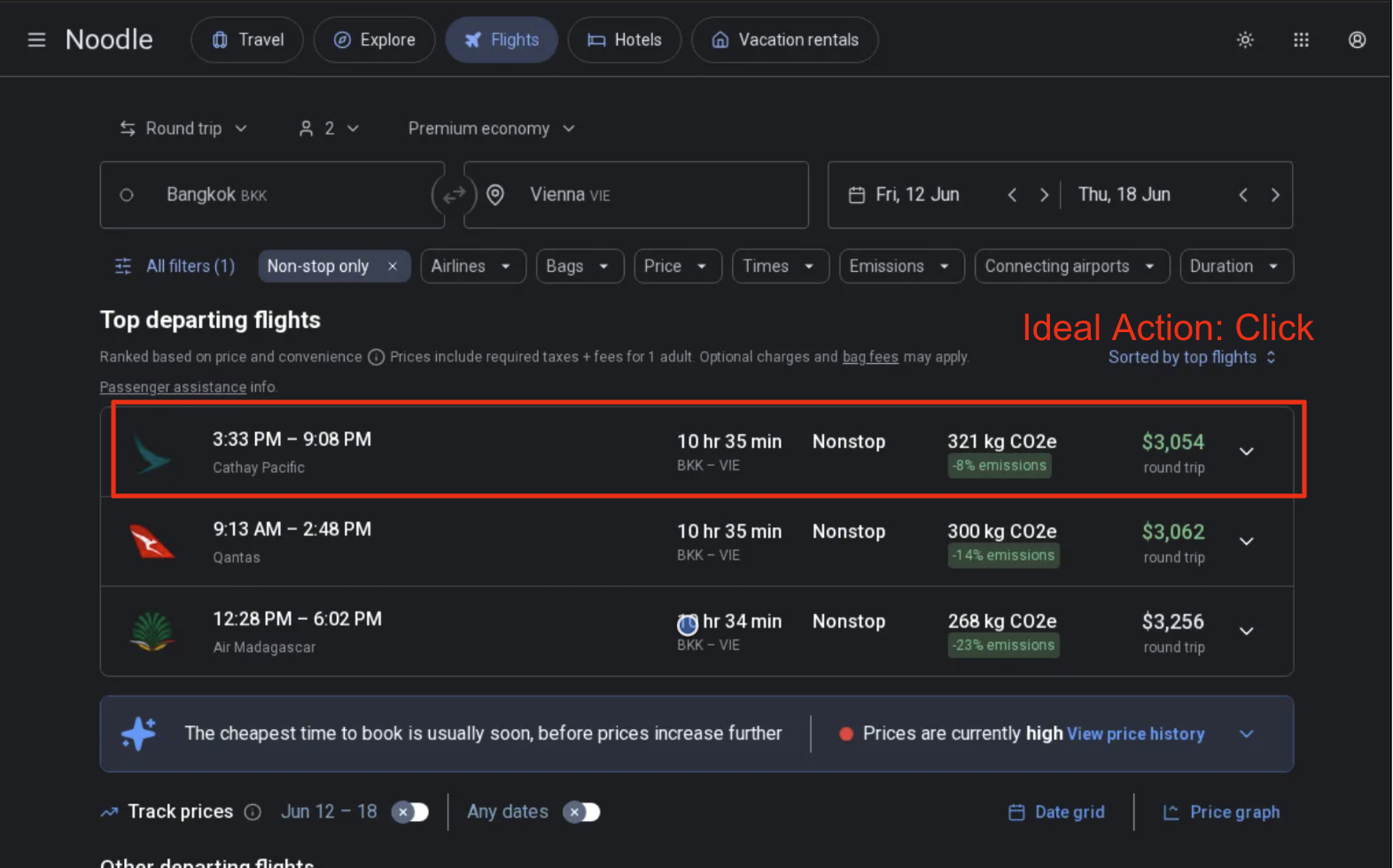
Task: Search for round-trip direct Premium economy class flights from BKK to VIE for 2 adult passengers. I want to see flight options for June 6-12, 2026, June 9-15, 2026, and June 12-18, 2026. Extract exact prices, flight numbers, and departure/arrival times for the cheapest option for each date range (if available).
Model Thoughts: Good! Now I can see the nonstop flights. The cheapest one showing is $3,256 for the 12:28 PM - 6:02 PM Air Madagascar flight. Now let me click on this flight to see the complete details.
Unfamiliarity with site navigation
Some websites exhibit behavior that is not automatically intuitive. For example, in the below example with Good Buy, the "Delivery Instructions" tab is below the address section. Therefore, it can be reasonably inferred that a user should save address instructions before applying delivery instructions. However, the real behavior of the site is that saving the address will close the delivery instructions tab, therefore not letting the agent apply those fields. This resulted in significant failures as the web agent struggled to learn this behavior.
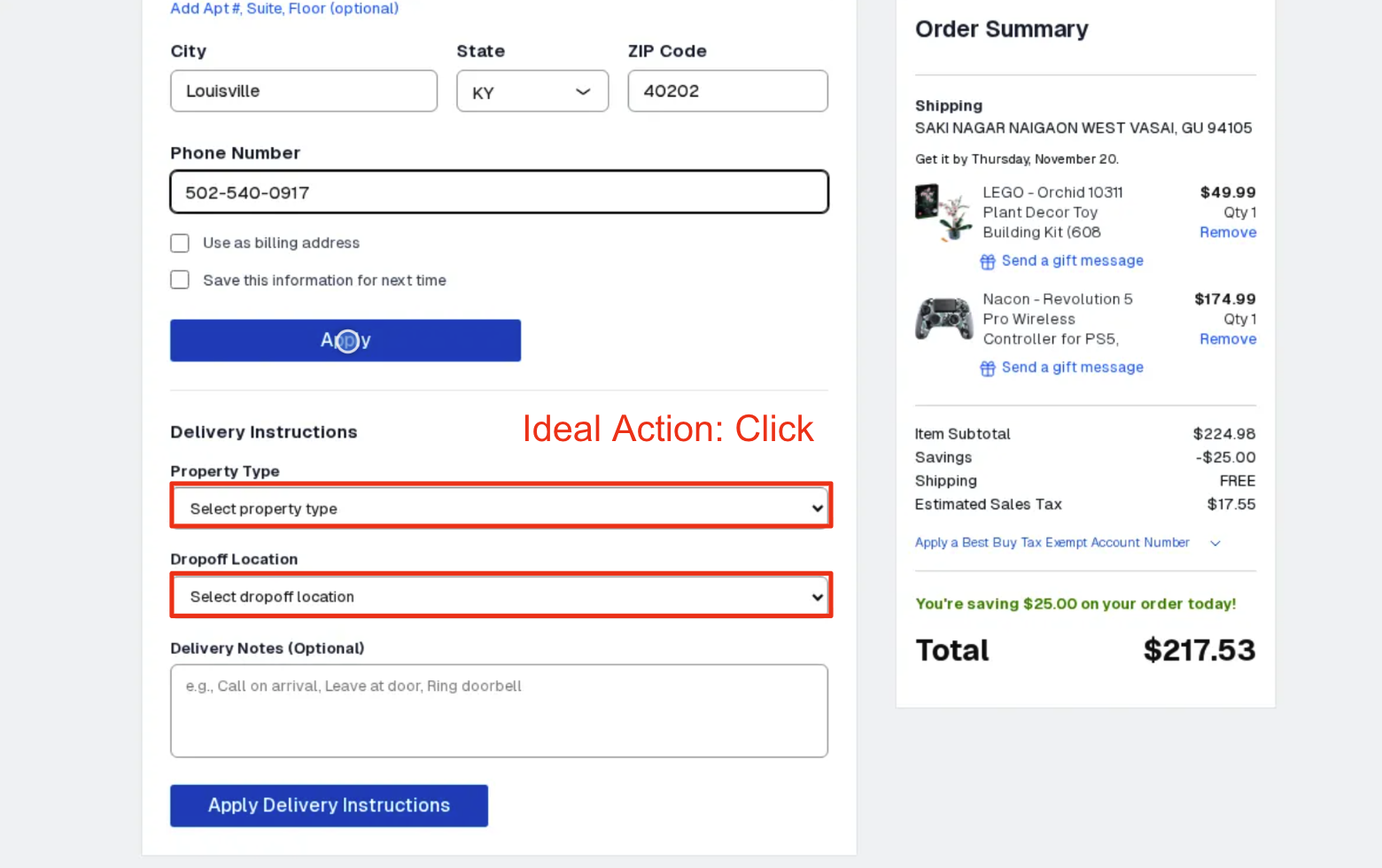
Task: Purchase the items in the cart and deliver them to Stephen Grantham. Use Stephen Grantham's payment info. Set the delivery instruction dropoff location to front door and property type to house. Your job is done when the order is successfully placed. Use guest checkout.
Model Thoughts: Perfect! The phone number has been entered. Now I need to click the "Apply" button to apply these address details before I can proceed to fill in the Delivery Instructions. Let me click the Apply button.
Limitations
Despite their advantages, building simulators present many challenges.
First, the upfront engineering work is significant: every workflow requires careful modeling, edge-case handling, and extensive QA. The biggest bottleneck was validating each simulator against real sites to fix the sim to real gap. Our engineers spent significant time reviewing screens side-by-side and closing small gaps in logic, structure, or data behavior.
Second, maintenance is non-trivial. Real websites evolve constantly, and simulators need periodic updates to stay representative. In one case, we modeled Japan Airlines end-to-end, only for the site to undergo a full redesign halfway through. These kinds of shifts mean simulators require ongoing attention, even though they remain far more stable than the live web.
Therefore, we believe that simulators are not the right approach for every workflow. They work best when the task is idiosyncratic (i.e. where similar flows don't exist elsewhere) or when no open-source, self-hosted alternatives capture the behavior you need. They are also especially valuable when deterministic verification is impossible or impractical on real sites (for example with payment flows).
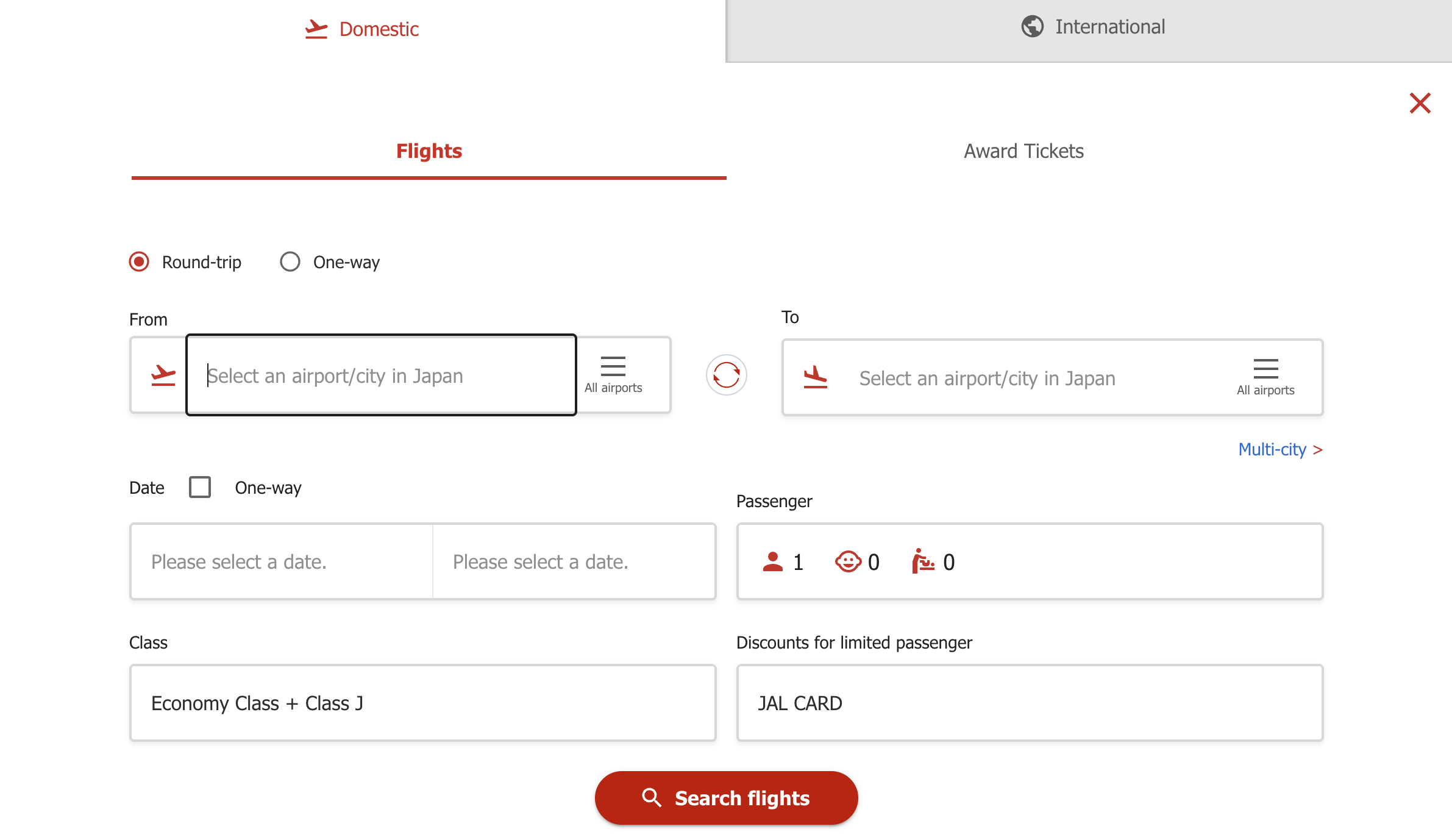 Old Design
Old Design
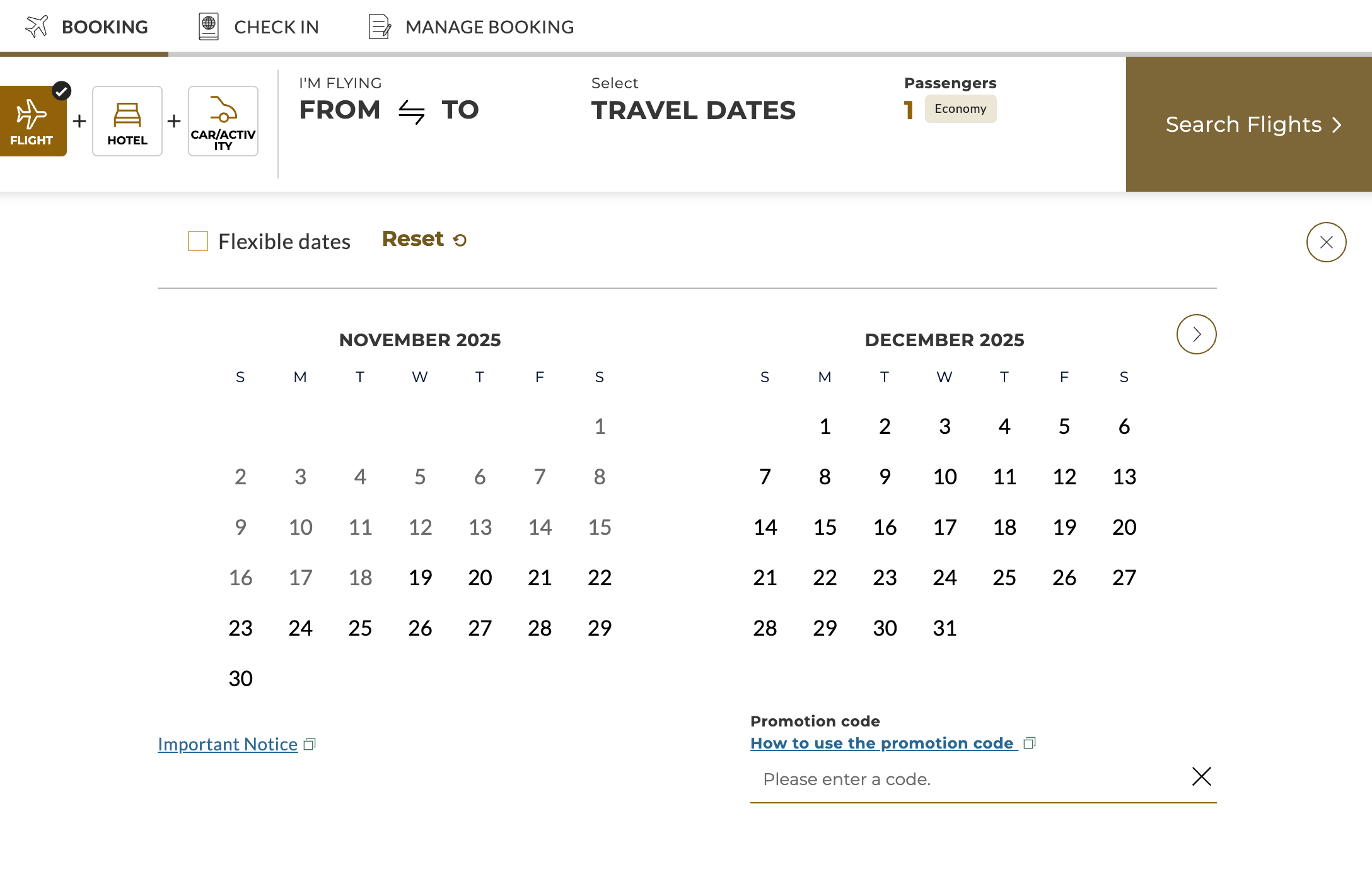 New Design
New Design
Future Work
The need for simulators and training environments will become an increasingly important part of AI development as verticalized agents mature into production. Some additional areas of work we are investing in today include:
RL/Post Training
A major advantage of simulator-based evaluations is that they double as training environments. We designed Westworld to be compatible with post-training and RL loops, and early results are promising. Our partners at Yutori leveraged Westworld to train their web agents, resulting in meaningful gains and SOTA performance. You can read more here.
Multi-Tool Environments
Future agents won't rely on the browser alone. We anticipate general agents will combine web use with APIs, tools, MCPs, code execution, and more. We're exploring multi-tool simulators that better reflect this hybrid workflow environment where agents can search, browse, query, and act within a trajectory.
Enterprise & Domain-Specific Environments
A growing focus for us is enterprise workflows, especially in financial services where tasks involve structured data, forms, excel, and multi-step reasoning. Simulators that reflect these real enterprise patterns will be critical for evaluating and training agents intended for production use in economically valuable workflows.
If you find this work interesting and want to help us build the next generation of agent training/testing environments we're hiring!
Contact: jerry@halluminate.ai
Contributors
Halluminate
Jerry Wu, Wyatt Marshall, Zeel Thakker, Vaibhav Lodhiya
Yutori
Rui Wang, Tong Xiao, Lawrence Chen, Eric Tay, Vamsi Aribandi, Devi Parikh, Dhruv Batra
Citation
If you find Westworld useful in your research, please cite our work:
@misc{westworld2025,
title={Westworld: Benchmarking and Training Web Agents in Highly Realistic Simulators via Verifiable Rewards},
author={Jerry Wu and Wyatt Marshall and Zeel Thakker and Vaibhav Lodhiya and Rui Wang and Tong Xiao and Lawrence Chen and Eric Tay and Vamsi Aribandi and Devi Parikh and Dhruv Batra},
year={2025},
url={https://github.com/Halluminate/westworld}
}