
The Adversarial Internet
The public internet is still an adversarial environment for web agents. Most websites rely on bot-detection systems like Cloudflare; tools originally designed to block "bad bots" such as scrapers, fraud scripts, and automated abuse.
However, a new class of agents has emerged. Web agents are often acting on behalf of real users with real intent: booking flights, checking out carts, updating CRMs, scheduling meetings, and navigating the web the same way a human would.
Despite this shift, the ecosystem hasn't adapted. Most website security systems lump these agents into the same category as traditional bots and prefer to block them outright. The result is a mismatch: users increasingly want autonomous web agents, yet the infrastructure of the internet is still optimized to stop anything that isn't a human-operated browser.
To survive in this environment, web agent teams have turned to a new layer of tooling: specialized browser infrastructure providers such as Anchor Browser, Browserbase, and others. These platforms promise stealth, stable fingerprints, proxy resilience, and the ability to pass through real-world bot checks that derail user requests.
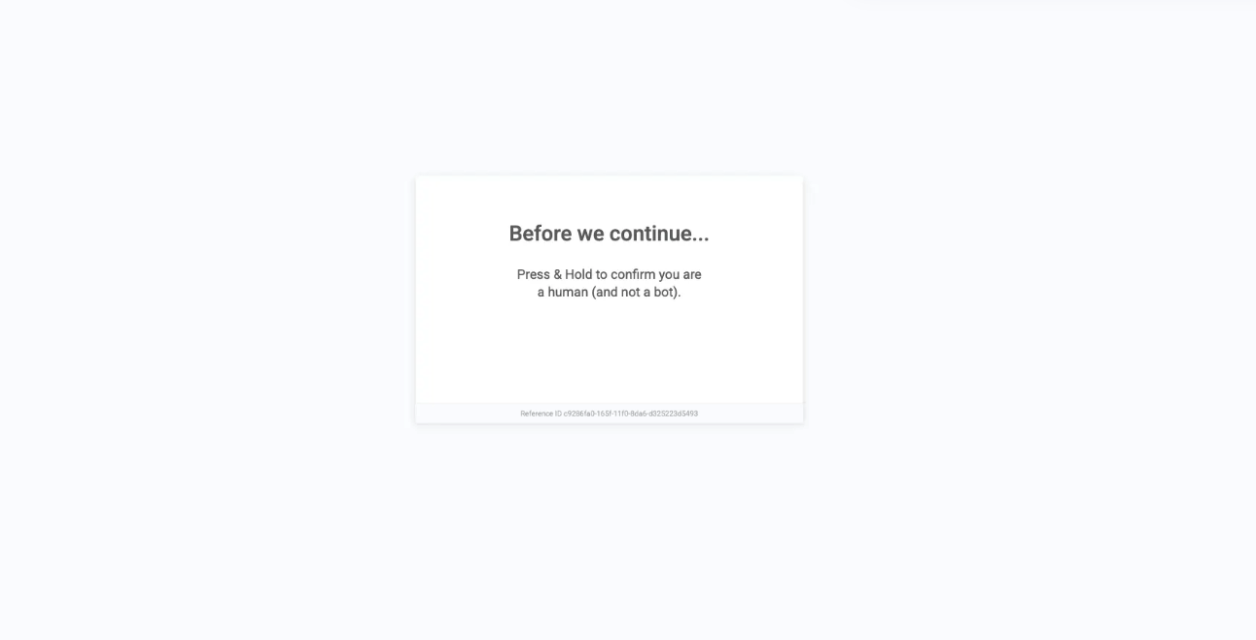 Bot Detection
Bot Detection
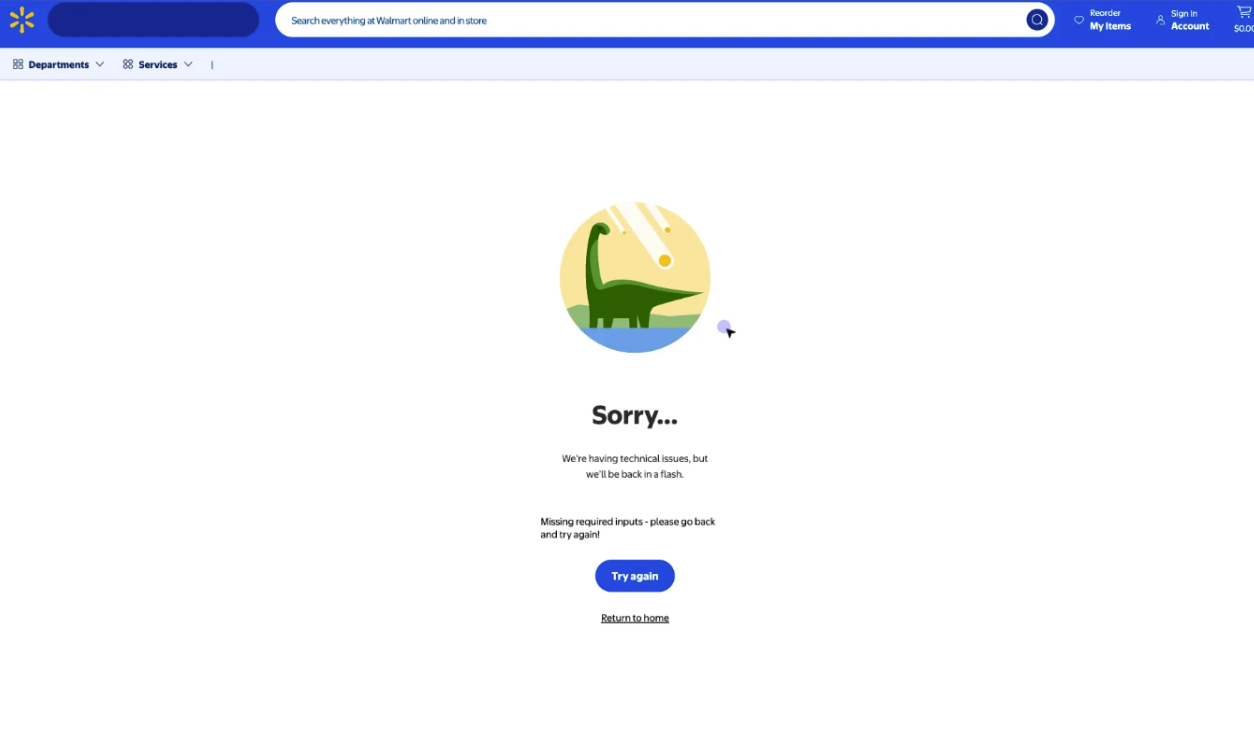 Walmart Block
Walmart Block
Browser infrastructure is now one of the biggest factors in whether a web agent works. In WebBench, we saw the same browser infrastructure issues could impact accuracy by 25-50%.
The problem is that there are no consistent ways to measure browser infrastructure performance. Most web agent benchmarks today focus on the model or the agent and not the infrastructure itself, therefore ignoring a key part of real-world web agent deployments.
Solution
Today we're releasing BrowserBench: the first benchmark built specifically to measure browser infrastructure for web agents.
BrowserBench includes 292 tasks across 292 different websites. Each task is a simple, read-based workflow that takes 5 - 25 steps. These aren't meant to challenge models - we anticipate most web agents should pass them. Rather, the real test is whether the browser infrastructure lets the agent act on the domain at all.
The sites span both public and commercial domains:
| Domain Type | Percentage |
|---|---|
| Commercial (.com) | 83% |
| Public (.gov, .edu, .org) | 17% |
For every provider, we measure its Stealth Failure Rate, defined as the number of agent trajectories that failed due to proxy and captcha issues. A lower stealth failure rate number indicates less proxy/captcha issues and therefore more reliable agent performance.
Benchmark Creation Methodology
Site Selection
To build BrowserBench, we started with real data from our earlier WebBench runs, which covered more than 450 real-world websites. From that set, we filtered for the sites with the highest rates of proxy and CAPTCHA failures. These issues were originally identified through human evaluation, which allowed us to rank sites by how frequently agents were blocked. We selected roughly the top 150 of these "high-friction" sites.
To balance the benchmark, we also added ~150 of the most popular websites on the internet. Specifically large, widely-browsed domains that any agent should be expected to handle.
The final 292 sites are a mix of important, high-traffic sites and sites known for strict bot-detection systems. This gave us a realistic, challenging, and representative testbed for browser infrastructure.
Top 10 Sites by Proxy/Captcha Issues from WebBench Evaluations
| Starting URL | Combined Proxy/Captcha Issues |
|---|---|
| alltrails.com | 57 |
| dickssportinggoods.com | 55 |
| crunchbase.com | 54 |
| open.spotify.com | 41 |
| deezer.com | 35 |
| crunchyroll.com | 33 |
| stackexchange.com | 28 |
| soundcloud.com | 27 |
| streeteasy.com | 24 |
| glassdoor.com | 22 |
Task Design
When designing the tasks we focused on simple, read-based workflows. The tasks were created with our annotation team. Each annotator navigates to the chosen sites and is instructed to create questions with clear, verifiable answers.
Tasks were scoped to be completed between 5 and 25 steps. This ensures the agent must navigate the site, but doesn't introduce unnecessary complexity that would make evaluation difficult. If the browser infrastructure works properly, the model should succeed. If the infra fails, the task should naturally fail.
| Task | Answer |
|---|---|
| Find the length in miles of the "Lands End Trail" in San Francisco. You must complete the task only using the starting website | 3.4 |
| What is the address of the dick's sporting goods location in Daly City, California? You must complete the task only using the starting website | 64 serramonte center |
| Who was the lead investor in OpenAI's pre-seed round? You must complete the task only using the starting website | Y Combinator |
| What is Eminem's number 1 most popular song? You must complete the task only using the starting website | Without Me |
| What is Ed Sheeran's number 1 top track according to Deezer? You must complete the task only using the starting website | Perfect |
Execution Methodology
For the benchmark, we held the agent and model constant to isolate the effect of browser infrastructure. We used:
- Browser Use as the agent framework
- GPT-OSS as the underlying model
We then selected four major browser infrastructure providers:
Each provider was evaluated in both its best Stealth setting and its Non-Stealth configuration. This allowed us to measure not just differences between providers, but the impact of stealth itself.
Evaluation Methodology
The benchmark evaluation consisted of two parts: human grading and LLM-as-a-judge.
For the primary results shown below, we relied on human reviewers. Annotators examined each trajectory and marked whether the agent was blocked by a proxy, CAPTCHA, or other bot-detection mechanism during the task. This produced a high-quality ground truth signal.
We then trained and calibrated an LLM judge to match human assessments. This judge is available as part of the BrowserBench open-source evaluation harness, so teams can run the benchmark automatically and reproduce our scoring.
| Metric | Autoeval Alignment |
|---|---|
| Stealth Failure Rate (proxy, captcha, etc) | 90.4% |
| Accuracy | 92.8% |
Results
Stealth Failure Rate is defined as the number of agent trajectories that failed due to proxy and captcha issues. A lower number here indicates a lower stealth failure rate and therefore more reliable agent performance.
| Provider | Stealth Failure Rate |
|---|---|
| Anchor Browser Stealth | 1.7% |
| Hyper Browser Stealth | 2.7% |
| Browser Base Stealth | 3.4% |
| Steel No Stealth | 4.7% |
| Anchor Browser No Stealth | 5.0% |
| Hyper Browser No Stealth | 6.5% |
| Steel Stealth | 6.8% |
| Browser Base No Stealth | 6.8% |
Anchor Browser's stealth mode stood out as the most reliable, triggering blocks only 1.7% of the time, with HyperBrowser Stealth and BrowserBase Stealth following up with performance of 2.7% and 3.4% respectively.
Generally, the stealth options for browser infrastructure systems worked better, with stealth options having an average proxy rate of ~3.65% while non-stealth options had an average proxy rate of 5.75%. HyperBrowser, Steel, and BrowserBase in non-stealth all hovered near 6.5 - 6.8%.
We also compared the rate of stealth failures relative to all agent failures and found browser infrastructure failures make up a large percent of problems.
| Failure Category | Percentage | Count |
|---|---|---|
| Stealth Failure Issues (Captcha/Proxy) | 15% | 118 |
| Other Issues | 85% | 668 |
The 15% failure rate amongst agent failures highlights how important browser infrastructure performance can be. Choosing the right provider and investing in browser infrastructure can significantly improve agent performance on a wide range of domain tasks.
Limitations
BrowserBench isn't a perfect reflection of every real-world workload. The tasks we use are simple, read-based queries, which may not capture the full complexity of production workflows. The website set also may not match your exact use cases; different domains have different bot-detection rules, so proxy and CAPTCHA rates can vary widely across the internet.
There's also some noise introduced by the agent and model. While we kept the agent (Browser Use) and model (gpt-oss) constant, reproducibility still depends on their variance. Most differences come from browser infrastructure, but the agent stack isn't completely deterministic.
BrowserBench gives a strong directional signal, but it shouldn't be treated as the final word for every application.
Conclusions
As browser agents become increasingly popular, it will become increasingly important for builders to choose the right browser infrastructure to deploy their agent. Up until today, there has not been a reliable way to accurately test browser infrastructure on a multitude of sites. We hope that BrowserBench will be an important step in building more reliable web agents.
If you find this work interesting or want to help us build the next generation of agent benchmarks and environments, we're hiring!
Contact: jerry@halluminate.ai
Authors
This work was done by the Halluminate team.
Citation
If you find BrowserBench useful in your research, please cite our work:
@misc{browserbench2025,
title={BrowserBench: The First Benchmark for Browser Infrastructure Stealth},
author={Halluminate Team},
year={2025},
url={https://browserbench.ai}
}